Hybrid
Dense + sparse retrieval
Vector similarity finds semantic matches even when wording differs. Keyword search catches exact identifiers, codes, and quoted phrases. Both run in parallel; results merge.
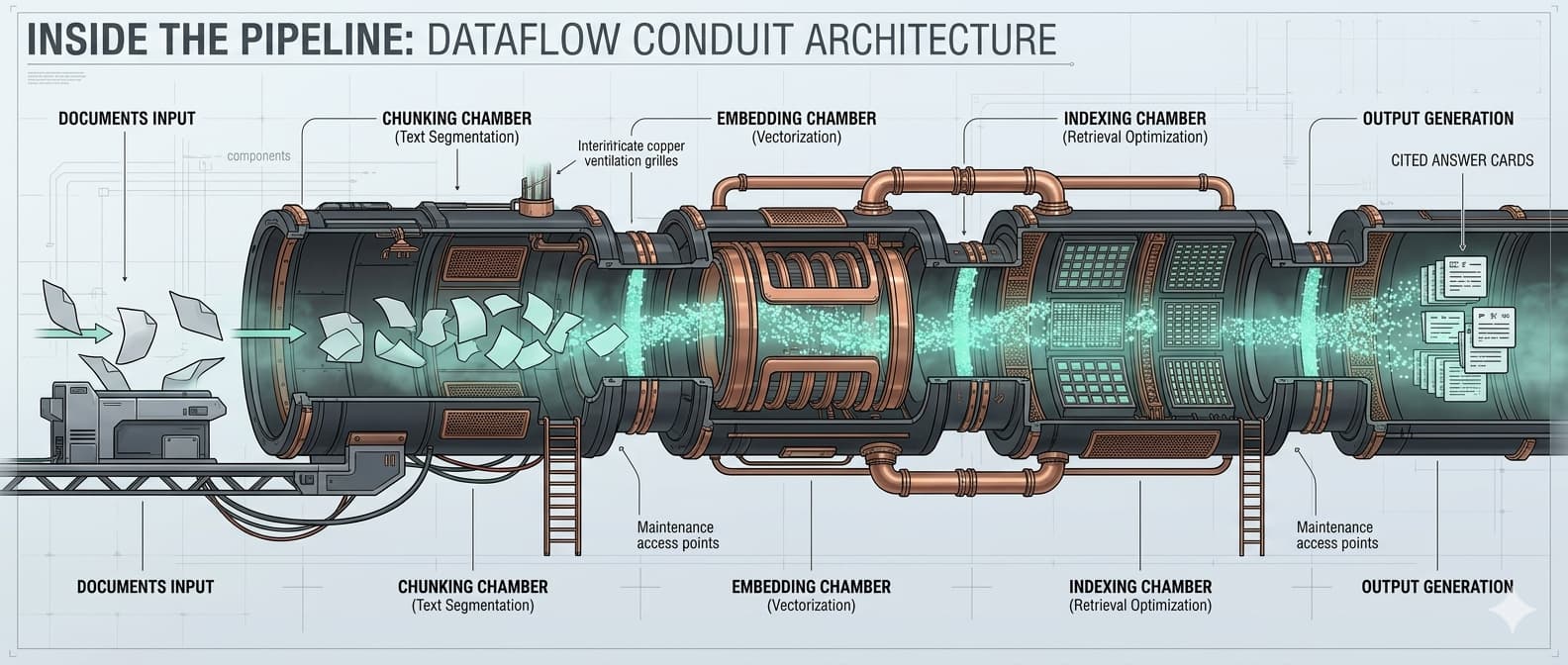
caveauAI is a multi-stage retrieval architecture, not a chat wrapper. Eight stages between document and cited answer, three deployment topologies, and a model layer you can swap. Built for engineers and CTOs evaluating private RAG seriously.
Each stage is independently observable, tunable, and replaceable. Stage boundaries are the points where compliance, audit, and customization happen.
Pure vector search is fragile on long-tail queries. caveauAI combines three retrieval mechanisms to surface evidence that actually answers the question.
Vector similarity finds semantic matches even when wording differs. Keyword search catches exact identifiers, codes, and quoted phrases. Both run in parallel; results merge.
Filter by date, author, document type, jurisdiction, client, or any custom field captured at ingest. Reduces noise on large corpora.
After initial retrieval, a smaller cross-encoder model scores query-chunk pairs to surface chunks that genuinely answer the question, not just chunks that match in vector space.
caveauAI is provider-agnostic at the model layer. Embeddings, retrieval re-ranker, and generation can each be swapped without rebuilding the corpus.
Run on Blue Note Logic GPU infrastructure or your own. Common choices: Llama, Mistral, Qwen — selected per corpus characteristics.
Routed via a unified gateway with key management, rate limiting, and request logging. Per-tenant policy on which providers are permitted.
Bring your own API key from any supported provider. Useful when you have an existing enterprise agreement or compliance posture.
When retrieval alone is no longer enough, Blue Note Logic can scope fine-tuning on a customer corpus. Available on Sovereign deployments.
The application, API surface, and tool behavior are identical across topologies. What changes is where the data sits and who operates the infrastructure.
Fastest path to running. Blue Note Logic operates the full stack in EU bare-metal datacenters with per-tenant corpus isolation.
Single-tenant deployment on dedicated infrastructure — Blue Note Logic bare-metal or your VPC (AWS, Azure, GCP).
Full caveauAI stack installed inside your perimeter. No outbound dependency on Blue Note Logic infrastructure or public model APIs.
Detailed API documentation lives on the all-features page. Short version below.
Standard REST endpoints for corpus management, retrieval, chat completion, and document lifecycle. API key auth with scoped permissions.
Expose caveauAI corpora to MCP-compatible agents (Claude Desktop, Cursor, custom agents). Grounds external assistants in your private knowledge.
Agent Builder chains retrieval, analysis, and delivery into repeatable pipelines. Trigger on incoming email, file drop, or schedule.
Blue Note Logic engineers will walk through caveauAI architecture against your existing data infrastructure, identity model, and compliance posture.