Corporate Memory Extraction & Sovereign Model Tuning
Turn your daily document workflows into a proprietary AI model you own

Most enterprise AI deployments follow the same pattern: rent access to a general-purpose model, send your data to someone else's infrastructure, and hope the vendor doesn't change their pricing or terms. When you cancel, you leave with nothing.
Corporate Memory Extraction inverts this model. We deploy a private AI engine inside your data perimeter. Your team uses it to do their real work — searching documents, answering questions, verifying citations. And while they work, the platform quietly builds the most valuable dataset in enterprise AI: a verified, domain-specific instruction set derived from expert behaviour.
That dataset becomes the foundation for a sovereign model — fine-tuned exclusively on your data, running on infrastructure you control, owned outright by your organisation.
The Three Phases
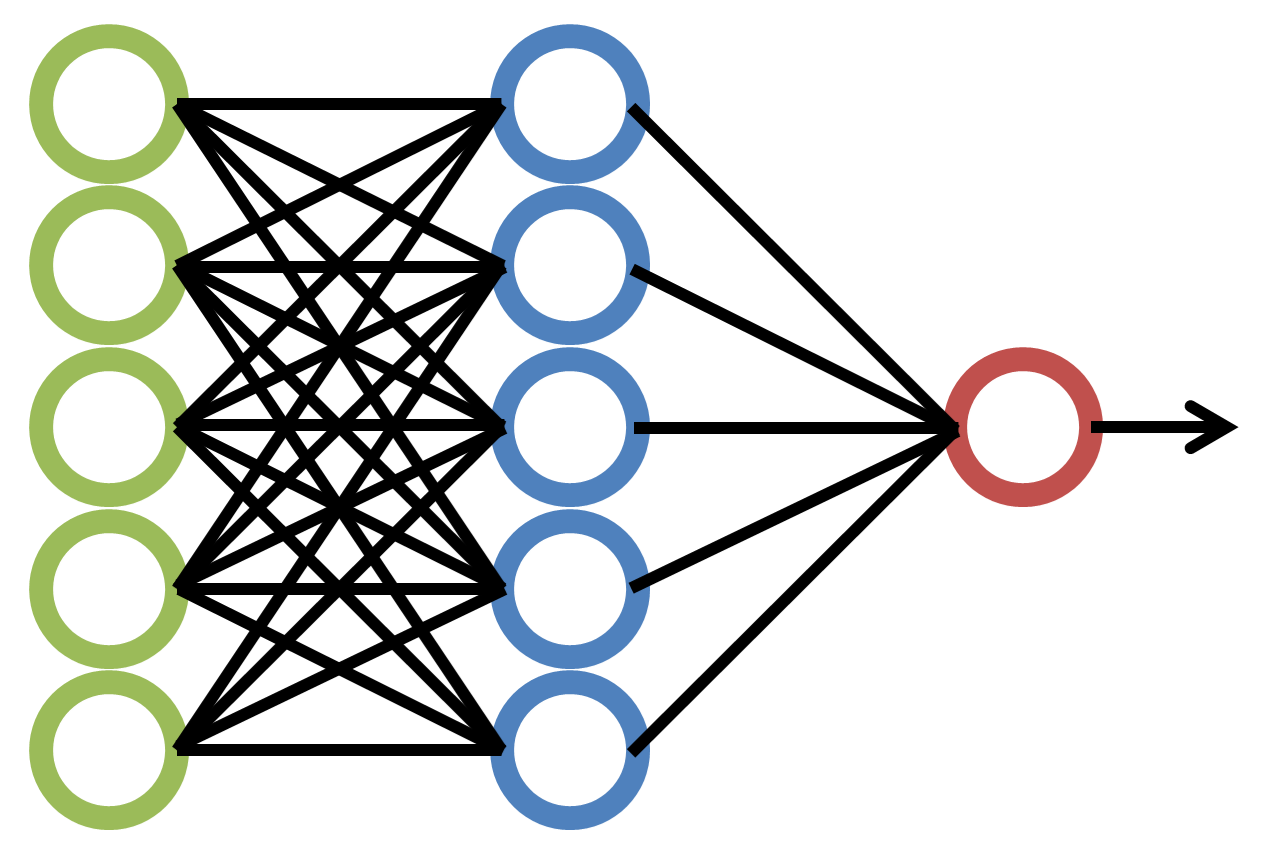
We deploy a secure, EU-hosted RAG (Retrieval-Augmented Generation) engine powered by open-source models up to 72 billion parameters. Your team uploads their working documents — contracts, case law, regulatory filings, internal manuals — and gets enterprise-grade search with cited answers from day one.
This solves the immediate problem: finding specific information buried in thousands of unstructured documents. Your legal team finds the relevant clause. Your compliance team locates the regulation. Your engineers find the procedure. Every answer links back to the exact source paragraph.
- ✓ 72B parameter open-source models (Qwen 2.5, custom fine-tunes)
- ✓ Vector, keyword, and hybrid search modes
- ✓ PDF, DOCX, TXT, HTML, Markdown — up to 50 MB per file
- ✓ Immediate ROI — answers in under 3 seconds


This is where the model diverges from every other enterprise search product.
While your team uses CorpusAI to do their jobs, every interaction is securely logged in your isolated MariaDB instance: the question asked, the context retrieved, the answer generated, and whether your domain expert accepted, refined, or rejected it. No extra annotation effort. No data labelling team. Your daily workflows produce the training data.
Once your organisation crosses the 10,000+ verified interaction threshold, we initiate the Forge. We extract the telemetry from your MariaDB, format it into instruction-tuning datasets, and route it to our heavy GPU infrastructure — dedicated NVIDIA RTX PRO 6000 Ada generation cards on Hetzner bare-metal.
We distill the massive 72B model's knowledge, combined with your specific corporate terminology, document structures, and expert judgement, into a specialised 8-billion parameter model tuned exclusively for your organisation.
We deploy your custom 8B model into your existing CorpusAI environment. The transition is seamless — your team keeps using the same interface, but the model behind it now understands your domain at a level no general-purpose AI can match.
The economics shift permanently in your favour:
- ✓ Runs faster — 8B parameters vs 72B means significantly lower latency
- ✓ Costs less — smaller model requires a fraction of the GPU compute
- ✓ Performs better — on your specific tasks, a tuned 8B outperforms a generic 72B
- ✓ Belongs to you — the model weights, the training data, and the inference pipeline are your property

Why This Matters to Your Organisation
Cost Reduction
An 8B model requires roughly 9x less GPU memory and compute than the 72B model it replaces. Your monthly infrastructure cost drops proportionally. The longer you use the platform, the better the economics become.
Zero Vendor Lock-in
The model is yours. The training data is yours. The weights file is yours. If you want to move it to your own infrastructure, you can. If you want to cancel our subscription, the model goes with you. Your investment compounds — it does not evaporate.
End-to-End Security
The entire pipeline — from the first query your team types to the final model weight file — never leaves our secure perimeter. WireGuard VPN tunnels between Hetzner bare-metal nodes. No cloud providers. No third-party AI APIs. No data leaves EU jurisdiction at any point in the process.
Infrastructure
The bottom line
Other vendors sell you access to their AI. We help you build your own. Every month your team uses CorpusAI, your sovereign model gets closer to production. When it ships, your infrastructure costs drop, your response times improve, and you own an asset no competitor can replicate.
Related Services
Document Intelligence Consulting
We help organisations design, deploy, and optimise caveauAI implementations — from corpus architecture to embedding strategy to production deployment.
Learn more
Knowledge Corpus Development
We help domain experts and organisations transform raw document collections into production-grade knowledge packages — structured, categorised, and optimised for AI-powered search. 80/20 revenue split in favour of the creator.
Learn more
Synthetic Data Engineering
We build custom synthetic data generation pipelines that preserve the statistical properties your models need while guaranteeing the privacy your regulators require.
Learn moreReady to Turn This Into a Live Programme?
We can scope the delivery model, identify the right team shape, and outline the fastest practical path forward.
Start the Conversation